



4. Disciplina i procés de la visualització de dades: "Big Data" i "Open Data"
4.1. Anàlisi d’un cas
Suposin que “trobem” això: “40”. El primer que ens ve al cap és “40 què?”. Ara imaginem que ens diuen “la temperatura del pacient és de 40 graus”. Hem dotat de significat el 40; quan la dada (40) és la resposta a una pregunta (“quina és la temperatura del pacient?”), hem avançat un nivell i ja podem parlar d’informació.
Però encara no som prou precisos. Què vol dir que “la temperatura del pacient és de 40 graus”? Doncs coses ben diferents:
-
Si són graus Celsius, el pacient té febre.
-
Si són graus Fahrenheit, el pacient és un cadàver fred.
-
Si són graus Kelvin, el pacient és un cadàver congelat flotant a l’espai.
Qüestions per reflexionar
-
Quins valors aporta a la ciutadania disposar de dades del sector públic?
-
Quin recursos, coneixements i quines eines ha de tenir la societat per poder gestionar tot el volum de dades que posseeixen les Administracions públiques?
-
Per què les Administracions públiques haurien de publicar les dades en formats oberts?
4.2. Disciplina i procés de la visualització de dades
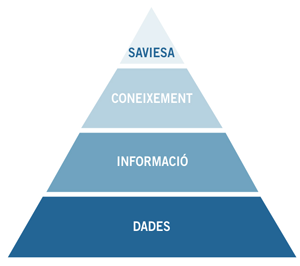
La disciplina de la visualització de dades consisteix a passar de la informació a la saviesa; per aconseguir-ho, cal el següent:
Dades → Informació → Coneixement → Saviesa
new_pdf_page
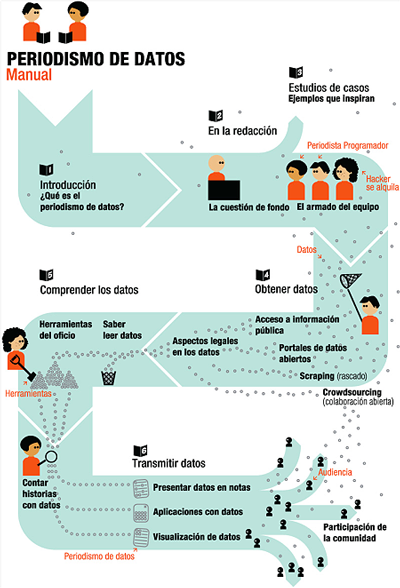
És molt similar al procés periodístic que podem veure en aquesta infografia (Rogers, 2011).
4.3. Concepte de dada
Una dada és la unitat bàsica de informació. És una representació simbòlica (numèrica, alfabètica, etc.) d'una entitat.
La dada no té valor semàntic (sentit) en si mateixa, però, convenientment tractada (processada), es pot emprar en la realització de càlculs o presa de decisions.
La gestió de les dades ens aportarà informació i, finalment, coneixement.
-
Una dada, sense context, no vol dir res.
-
El format (en un sentit ampli) de representació de la dada és important.
-
Les dades tenen unitats i un rang associat.
 Per tant, aquest context que comentàvem (format, unitats i rangs) és el que dóna significat a una dada i la converteix en informació que respon una pregunta. Quan tenim molta informació (i, per tant, moltes dades), podem inferir nova informació combinant diferents fonts, creant coneixement.
Per tant, aquest context que comentàvem (format, unitats i rangs) és el que dóna significat a una dada i la converteix en informació que respon una pregunta. Quan tenim molta informació (i, per tant, moltes dades), podem inferir nova informació combinant diferents fonts, creant coneixement.
És aquest coneixement el que perseguim, construint-lo combinant moltes fonts d’informació. Aquesta estructura es coneix com la jerarquia DIKW (Data-Information-Knowledge-Wisdom).
En el nostre context, però, per “dades” entenem normalment taules de dues dimensions que representen, per cada fila, un element, i per cada columna un valor associat a un atribut de l’element, de forma que cada element queda descrit mitjançant els seus atributs.
Però les dades (obertes o no) no són només taules. Hi ha molts altres tipus de dades que tenim disponibles. Una entrada a un blog n’és un, “informació textual”, amb les seves particularitats: manca d’estructura clara, format i contingut entrellaçats, etc. Com ja veurem més endavant, la complexitat de manipular dades és directament proporcional a la seva manca d’estructura.
4.4. Com podem definir "Big Data?"
Es parla de Big Data quan tenim un gran nombre de dades per a una o més causes, les tres V:
-
Volum: si tenim un “gran” nombre d’elements.
-
Varietat: si comptem amb un “gran” nombre de variables que descriuen cada element.
-
Velocitat: si disposem d’una “gran” taxa d’actualització de les dades.
 Però Big Data també implica un canvi de paradigma: ja no treballem només amb mostres o subconjunts de les dades; per primer cop pensem en la totalitat de la població o l’univers, i podem prendre decisions sense haver d’estimar realment com d’exacte és la nostra anàlisi.
Però Big Data també implica un canvi de paradigma: ja no treballem només amb mostres o subconjunts de les dades; per primer cop pensem en la totalitat de la població o l’univers, i podem prendre decisions sense haver d’estimar realment com d’exacte és la nostra anàlisi.
L’estadística ens permet calcular l’error que cometem quan mesurem quelcom tenint en compte quants elements tenim, és a dir, la N. En qualsevol estudi estadístic, veureu normalment que s’hi parla de marges d’error i s’explicita la N i també un valor anomenat p que ve a ser la probabilitat que allò que s’està mesurant o analitzant s’hagi trobat per atzar.
new_pdf_page
4.5. Què són les dades obertes?
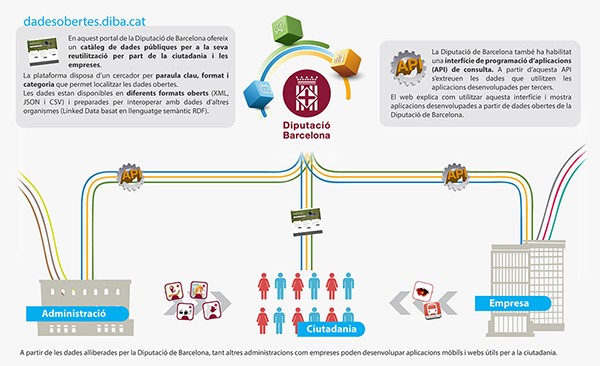
Què són les dades obertes?, infografia de la Diputació de Barcelona.
A El futur obert, de David Wiley (2010), s’hi defineix què vol dir obert, però en un context de recursos educatius, tot i que és fàcil extrapolar entre continguts i dades.
De forma resumida, l’autor defineix un contingut com obert quan tenim la possibilitat de realitzar diferents accions, les 4 R:

-
Reutilitzar: el dret a reutilitzar el contingut en forma inalterada/literal (per exemple, usant-lo tal qual).
-
Revisar: el dret a adaptar, ajustar, modificar o alterar el contingut (per exemple, traduint-lo a un altre idioma).
-
Remesclar: el dret a combinar el contingut original o revisat amb un altre contingut per crear un producte nou (per exemple, integrar el contingut en una remescla).
-
Redistribuir: el dret a compartir còpies del contingut original, de les revisions o de les remescles amb altres (per exemple, donar una còpia del contingut a un conegut).
El propi autor, recentment, ha ampliat aquesta definició d’obert amb una 5a R:
-
Retenir: el dret a fer còpies i posseir-ne una del contingut original.
new_pdf_page
4.6. Aspectes legals i tecnològics sobre dades obertes
En l’àmbit dels aspectes legals, s’hi poden destacar els elements següents:
-
Transparència: una institució disposa de dades que poden ser d’interès general; està obligada a publicar-les? Veurem que, en el cas de l’Administració pública, hi ha lleis que regulen la reutilització dels documents elaborats o custodiats per Administracions i organismes del sector públic. És un dels tres pilars en els quals es fonamenta un govern obert, juntament amb la participació i la col·laboració.
-
Privacitat: si aquestes dades fan referència a tercers, poden publicar-se tal qual? És necessari fer anònimes les dades publicades de forma que no sigui possible identificar individus (o institucions) de forma unívoca.

-
Copyright i llicències (condicions d’ús): aquestes dades, com poden ser reutilitzades? Quines operacions es poden efectuar amb elles? Les dades, com a fets que descriuen la realitat, no es poden patentar. Aquest tema és el més delicat i segurament també el més complex, especialment per la diversitat de llicències i el problema de combinar diferents llicències en el cas d’estar remesclant continguts (incloent-hi dades) amb llicències diferents. Poc a poc comença a haver-hi llicències específiques per a dades obertes, tot i que encara no és habitual trobar-les.
-
Traçabilitat: en un món digital, on es pot crear una còpia idèntica a cost zero i sense malmetre l’original, és impossible poder conèixer-hi sempre quin és l’origen de les dades, excepte si aquest s’indica de forma explícita en les mateixes. L’origen de les dades és una dada sobre les dades (és a dir, una metadada), així que ha de formar part de la seva descripció.
-
Qualitat: qui és responsable de les dades? Què passa si les dades contenen errors en origen o bé són reutilitzades erròniament (potser manipulant-les malintencionadament)? El problema principal aquí és definir què entenem per qualitat. La qualitat no és només tenir una dada fiable sinó també actualitzada, ben descrita, amb precisió suficient, etc.
-
Gratuïtat: han de ser gratuïtes les dades obertes? Aleshores, com es poden cobrir els costos de publicació? Es poden establir taxes o costos per a la seva reutilització? Es pot cobrar per unes dades amb una llicència que obliga a publicar les obres derivades també en obert? Es pot cobrar per dades que provenen de processos pagats amb els nostres impostos?
En relació amb els aspectes tecnològics, ens centrarem més en les dades i els formats per al seu emmagatzemament i accés.
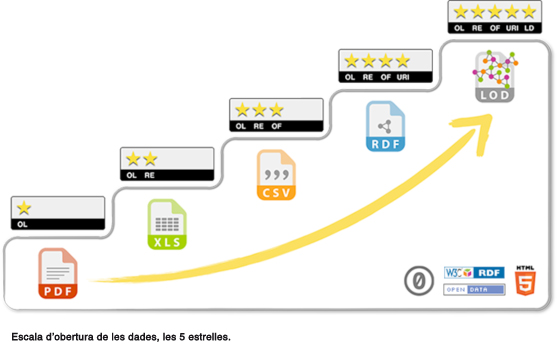
Hem vist que, per poder dir que les dades són obertes, hem de poder executar les 5 R, és a dir, accedir-hi, manipular-les i redistribuir-les, sense impediments legals ni tecnològics. Suposarem ara que tenim els aspectes legals resolts, i ens centrarem en els aspectes tecnològics que cal tenir en compte. Quins són? S'està fent referència a allò que es coneix com esquema de les 5 estrelles.
En relació amb l’obertura de dades reutilitzables, cal arribar al tercer nivell com a mínim: compartir la informació de forma que sigui senzill manipular-la, sense obligar l’usuari final a disposar d’un programari específic amb llicència. Formats oberts, n’hi ha molts, depenent del tipus d’informació que s’emmagatzema. Es pot preparar i penjar un fitxer CSV a Internet, de forma que tothom pugui accedir-hi lliurement i reutilitzar la informació sobre els reculls de notícies.
 És evident que seria interessant poder accedir només a la informació que un desitja, i no haver de descarregar la totalitat de les dades. A més, els potencials usuaris volen informació actualitzada.
És evident que seria interessant poder accedir només a la informació que un desitja, i no haver de descarregar la totalitat de les dades. A més, els potencials usuaris volen informació actualitzada.
El fitxer CSV representa una fotografia o un accés estàtic de la realitat dels reculls de les notícies en un moment donat, per la qual cosa resulta millor proporcionar un accés dinàmic que permeti als usuaris realitzar consultes sobre el fitxer. Això permetria recuperar només la informació desitjada i fer cerques més complexes; d’aquesta manera, l’usuari que fa la cerca només recupera un trosset del fitxer CSV original, amb la informació que realment desitja. Aquestes cerques predefinides rebrien un paràmetre (o més si s’escau) i retornarien la informació desitjada, potser també en un fitxer CSV, però molt més petit, reduint el temps necessari per descarregar-lo. El resultat d’aquestes cerques s’acostuma a retornar utilitzant un tipus de fitxers específic per intercanviar dades amb una certa estructura interna, com ara XML.
Ho entendrem millor aprofitant un exemple que la Generalitat de Catalunya posa a disposició de tots nosaltres mitjançant el seu portal de dades obertes. Es tracta del fitxer amb els equipaments de Catalunya Dades obertes gencat, un recull de més de 35.000 equipaments amb un munt d’informació sobre cadascun. Aquest recull, tot i que està disponible en diversos formats, podem dir que, en versió original, està en format RDF. Doncs bé, aquest fitxer “pesa” gairebé 44 MB, el que impossibilita descarregar-lo en segons quin dispositiu i quina connexió tinguem disponible. En canvi, la Generalitat de Catalunya ofereix un servei, un cercador d’equipaments, que permet descarregar només la informació desitjada.
Per accedir a tot un conjunt de dades de cop pot ser ineficient: potser no ens interessa tota la informació, sinó només un subconjunt de files i/o columnes d’acord amb uns criteris de cerca. Aquest accés dinàmic basat en cerques és el primer pas cap a un veritable servei de dades obertes, on els usuaris i, més important encara, les aplicacions poden accedir només a allò que els interessa. Tanmateix esdevé clau poder localitzar les dades usant descriptors textuals.
De fet, és la possibilitat d’accedir a dades d'orígens diferents la que pot crear coneixement i afegir valor. La “R” de remesclar és, en aquest sentit, la més interessant.
new_pdf_page
4.7. Treballem amb dades obertes: eines
En funció del seu objectiu i de les seves característiques, podem classificar una eina en una o més categories:
-
Captura: inclouríem aquí aquelles eines que permeten capturar dades a partir d’una font o d’un origen. L’objectiu d’aquestes eines és acabar disposant de les dades en un format que ens permeti manipular-les a posteriori (per exemple, una o més taules).
-
Procés: són eines que permeten manipular (en un sentit ampli) les dades, com ara combinar una o més taules, calcular camps nous, fer conversions de format, filtrar d’acord a uns certs criteris, etc. És a dir, a partir d’un munt de dades disperses en una o més taules, quedar-nos amb el subconjunt que realment ens interessa per analitzar-lo posteriorment (o bé publicar-lo com un nou conjunt de dades).
-
Anàlisi: en aquest cas parlem d’eines que permeten fer una anàlisi del contingut de les dades, com ara calcular els descriptors estadístics, buscar patrons en les dades, aplicar tècniques pròpies de la mineria de dades per fer-ne una classificació, construir models que expliquin el comportament de certa variable, etc.
-
Visualització: finalment, un dels aspectes més interessants de les dades és generar visualitzacions de les dades mateixes o dels resultats obtinguts durant la seva anàlisi, amb l’objectiu de mostrar clarament el seu valor.
Hem de poder accedir a les dades mitjançant un fitxer tipus CSV o XML, o bé a través d’una aplicació que ens retorni la informació desitjada a partir d’uns paràmetres de cerca.
De vegades no sempre és possible fer-ho, però, ja que la informació només es publica a la web en formats pensats pels humans, incloent-hi la navegació per les diferents pàgines web que la composen, i no està pensada per poder automatitzar el procés i descarregar tota la informació desitjada amb un sol clic.
L’anàlisi i la visualització permeten extreure informació de les dades, un cop aquestes estan en el format i l'estructura adequats per a la seva anàlisi.
La tècnica coneguda com a web scraping està pensada per extreure informació de webs de forma automàtica o semiautomàtica; d’aquesta manera no caldrà copiar la informació que trobem a Internet en formats que ens permeten la seva explotació. Consisteix a esbrinar l’estructura i els paràmetres de les pàgines web que contenen la informació desitjada, programar uns petits scripts que capturin totes les pàgines web en format HTML i fer un altre script que sigui capaç de processar les pàgines web descarregades i extraure’n la informació desitjada, generant un fitxer CSV o similar.
Per poder analitzar i visualitzar les dades, ens cal haver-les capturat i preprocessat. Tot i que ja hem vist que, amb una bona descripció i l’ús d’un format apropiat, es poden publicar dades en obert, sempre serà necessari disposar d’eines que ens ajudin a fer conversions de formats, fusionar dos o més fonts de dades, seleccionar les que ens interessen d’un conjunt més gran, etc. És aquest pas el més complicat i que requereix més competències de l’àmbit de l’enginyeria, en un sentit de “resoldre problemes”. Altres cops, amb l’ús d’una eina puntual, serà possible resoldre un problema concret.
new_pdf_page
4.8. Bones pràctiques de dades obertes
Tot i que ja hem vist i usat alguns exemples de fonts de dades, podem aprofitar per fer un petit recull i obrir un debat sobre la necessitat d’endreçar una mica el panorama des del punt de vista dels productors, però pensant en els/les usuaris/àries finals. És a dir, com posar a disposició dels mediadors i dels consumidors les dades obertes i, sobretot, com proporcionar mecanismes per obtenir feedback de la comunitat d’usuaris.
En l'àmbit català, tenim actualment els ens locals molt actius publicant dades obertes, entre d’altres, la Diputació de Barcelona, l’Ajuntament de Barcelona (OpenDataBCN), l’Ajuntament de Sabadell (OpenData SBD), l’Ajuntament de Badalona (Opendata Badalona) o l’Ajuntament de Granollers (Dades Obertes Granollers).
També podem trobar altres grans productors de dades, com són la Generalitat de Catalunya (Dades obertes gencat), l’Institut d’Estadística de Catalunya (IDESCAT) o l’Institut Cartogràfic I Geològic de Catalunya (ICGC).
A l'Estat espanyol, hi ha també un munt d’administracions i organitzacions de diferent mida que publiquen dades en obert com l’Ayuntamiento de Zaragoza, la Xunta De Galicia (abert@s) o l’estat (datos.gob.es).
En l’àmbit internacional, podem destacar-hi els següents, al Regne Unit (data.gov.uk), als Estats Units d’Amèrica (data.gov) o a la Unió Europea (Open Data Portals), tot i que aquest darrer, més que proporcionar accés a dades obertes, descriu les polítiques i accions que està seguint la Unió Europea respecte a les dades obertes.